
今回は、選手の成績推移について
複数の選手の比較という観点で解析してみます。
前回は、一人の選手 プホルス選手に着目して
分析してみました。
参考は例によって偉大なる著書
Rによるセイバーメトリクス入門です。
事前準備
Lahmanパッケージのbattingには
全選手の成績が格納されています。
そこから、通算打席を算出し、
2000打席以上の選手を抽出しました。
batting%>%
group_by(playerID)%>%
summarize(Career.AB = sum(AB, na.rm = TRUE))%>%
inner_join(batting, by = "playerID")%>%
filter(Career.AB >= 2000)-> batting_2000年間300打席だとしても、
7年ぐらいはかかりますね。
Fieldingには選手とポジションのデータが格納されています。
そこから、最も出場機会の多いポジションを抽出します。
Fielding%>%
group_by(playerID, POS)%>%
summarize(Games = sum(G))%>%
arrange(playerID, desc(Games))%>%
filter(POS == first(POS))->Positions
そして、batting_2000のデータに結合します。・・・
(年間の成績に、出場機会の多いポジションとゲーム数が結合される)
batting<- batting_2000%>%
inner_join(Positions, by = "playerID")
通算成績を計算
varsとして、各指標を格納
vars <- c("G", "AB", "R","H","X2B","X3B",
"HR","RBI","BB","SO","SB")それをもとにて、通算成績を計算します。
batting%>%
group_by(playerID)%>%
summarize_at(vars, sum, na.rm=TRUE)
->C.totals
追加で打率と、長打率を算出します。
C.totals%>%
mutate(AVG = H/AB,
SLG = (H-X2B-X3B-HR +2*X2B+
3*X3B+4*HR)/AB)
->C.totals
Positionsのデータを結合して、
ポジションに応じた、
基準値を付与します。
C.totals%>%
inner_join(Positions, by = "playerID")%>%
mutate(Value.POS = case_when(
POS=="C"~240,
POS=="SS"~168,
POS=="2B"~132,
POS=="3B"~84,
POS=="OF"~48,
POS=="1B"~12,
TRUE~0
))
->C.totals類似性スコアの計算
Bill Jamesは選手の比較をするために
類似性スコアというものを開発しました。
1000点からスタートして、各指標についてポイントを引いていきます。
- 20試合
- 75打席
- 10得点
- 15安打
- 5二塁打
- 4三塁打
- 2本塁打
- 10打点
- 25四球
- 150三振
- 20盗塁
- 打率0.001
- 長打率0.002
最後にポジションの基準値を引きます
この指標を求め、類似する選手を抽出する
similar関数を作成します。
similar <- function(p, number=10){
C.totals %>%filter(playerID == p)->P
C.totals%>%
mutate(sim_score = 1000-
floor(abs(G-P$G)/20)-
floor(abs(AB-P$AB)/75)-
floor(abs(R-P$R)/10)-
floor(abs(H-P$H)/15)-
floor(abs(X2B-P$X2B)/5)-
floor(abs(X3B-P$X3B)/4)-
floor(abs(HR-P$HR)/2)-
floor(abs(RBI-P$RBI)/10)-
floor(abs(BB-P$BB)/25)-
floor(abs(SO-P$SO)/150)-
floor(abs(SB-P$SB)/20)-
floor(abs(AVG-P$AVG)/0.001)-
floor(abs(SLG-P$SLG)/0.002)-
abs(Value.POS - P$Value.POS)
)%>%
arrange(desc(sim_score))%>%
head(number)
}
前回解析したプホルス選手について求めます。
similar(pujols_id,6)playerID G AB R H X2B X3B HR RBI BB SO SB
<chr> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 pujolal01 2971 11114 1872 3301 672 16 679 2150 1345 1349 116
2 mayswi01 2992 10881 2062 3283 523 140 660 1903 1464 1526 338
3 palmera01 2831 10472 1663 3020 585 38 569 1835 1353 1348 97
4 murraed02 3026 11336 1627 3255 560 35 504 1917 1333 1516 110
5 robinfr02 2808 10006 1829 2943 528 72 586 1812 1420 1532 204
6 aaronha01 3298 12364 2174 3771 624 98 755 2297 1402 1383 240
Will Mayers, Rafael Palmeiro, Eddie Murray,Frank Robinson, Henry Aaron
ちょっとわからないのですが・・・
みんな3000本に近い、超えてくる安打数を誇っています。
成績推移に対するフィッティングとプロット
では、2000打席以上の選手について
選手IDで統合して、各成績の通算成績を算出
さらに長打率・出塁率、OPSを算出します。
batting_2000%>%
group_by(playerID, yearID)%>%
summarize(G=sum(G), AB=sum(AB),R=sum(R),
H=sum(H),X2B=sum(X2B),X3B=sum(X3B),
HR=sum(HR),RBI=sum(RBI),SB=sum(SB),
CS=sum(CS),BB=sum(BB),SH=sum(SH),
SF=sum(SF),HBP=sum(HBP),
Career.AB=first(Career.AB),
POS=first(POS))%>%
mutate(SLG=(H-X2B-X3B-HR+2*X2B+3*X3B+4*HR)/AB,
OBP=(H+BB+HBP)/(AB+BB+HBP+SF),
OPS=SLG+OBP)
->batting_2000そうしたら、年齢データを追加します。
(MLBのデータは7月が年齢の区切りでしたね。)
batting_2000%>%
inner_join(People, by = "playerID")%>%
mutate(Birthyear = ifelse(birthMonth >=7,
birthYear +1, birthYear),
Age = yearID-Birthyear)
->batting_2000
そうしたら、類似性スコアの近い選手の
年齢とOPSの推移をグラフ化します。
player.listとして類似性スコアの近い人をリストアップ
リストアップされた選手をグラフ化します。
plot_trajectories <- function(player, n.similar=5, ncol){
flnames <- unlist(strsplit(player, " "))
People%>%
filter(nameFirst==flnames[1],
nameLast==flnames[2])%>%
select(playerID)->player
player.list<- player%>%
pull(playerID)%>%
similar(n.similar)%>%
pull(playerID)
+
batting_2000%>%
filter(playerID %in% player.list)%>%
mutate(Name=paste(nameFirst, nameLast))->Batting.new
ggplot(Batting.new, aes(Age, OPS))+
geom_smooth(method = "lm",
formula = y~x+I(x^2),
size=1.5)+
facet_wrap(~ Name, ncol=ncol)+theme_bw()
}
プホルスの類似性スコアが近い人について、
そのOPSの成績推移をグラフ化してみます。
plot_trajectories("Albert Pujols", 6, 2)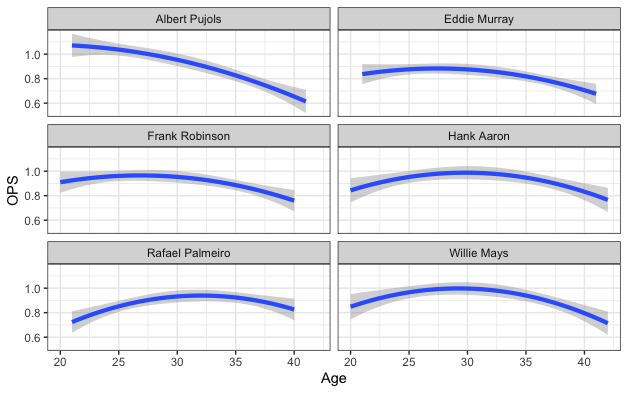
自分も勘違いしていたのですが、
類似性スコア=最終的な成績の類似性
上のグラフ=それに至る成績推移
となります。
最後に、成績推移のピークと、成績の曲率について解析します。
dj_plot<-plot_trajectories("Albert Pujols", 9, 3)regressions <- dj_plot$data%>%
split(pull (., Name))%>%
map(~lm(OPS~I(Age-30)+I((Age-30)^2),data =.))%>%
map_df(tidy, .id= "Name")%>%
as_tibble()解析したデータから、最大値と曲率を計算します。
regressions%>%
group_by(Name)%>%
summarize(
b1=estimate[1],
b2=estimate[2],
Curve=estimate[3],
Age.Max=round(30-b2/Curve/2,1),
Max=round(b1-b2^2/Curve/4,3)
)
->S最後にグラフ化してみます。
ggplot(S, aes(Age.Max, Curve, label=Name))+
geom_point()+geom_label_repel()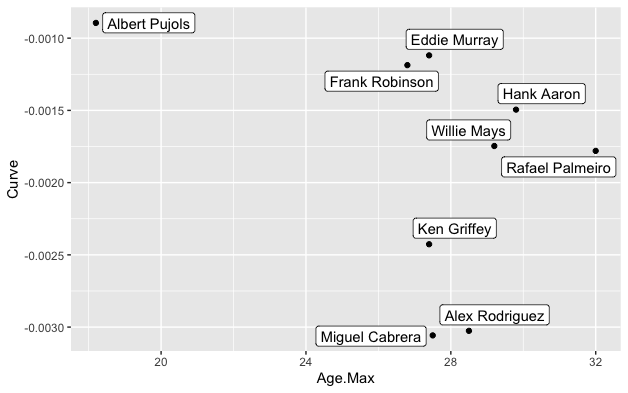
はい!できました!
プホルスは、Age.Maxが低く、Curveが大きい
つまり、若くしてピークを迎えましたが、
成績の低下は非常に緩やかだったということですね
対極にあるのがRafael PalmeiroやAlex Rodoriguezといった選手でした。
